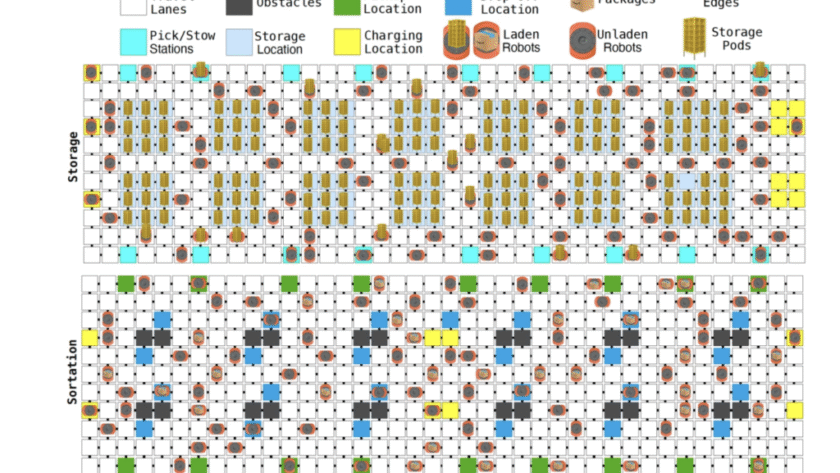
Amazon has reached a remarkable milestone by deploying its one-millionth robot across global fulfillment and sortation centers, solidifying its position as the world’s largest operator of industrial mobile robotics. This achievement coincides with the launch of DeepFleet, a groundbreaking suite of foundation models designed to enhance coordination among vast fleets of mobile robots. Trained on…