
TLDR Content‑generation AI and Code‑generation AI together soak up ≈ $50 B+ in U.S. VC capital, dwarfing every other category. Cyber‑Sec, RPA, and Conversational AI - lead enterprise deployment charts. They win on clear ROI, fast time‑to‑value, and rich vendor ecosystems. 1. Use-Cases with the Widest Enterprise Adoption We’ve established that Enterprise spend on AI will be…
admin

Image by Author | Ideogram
# Introduction
Picture this: you're working on a Python project, and every time you want to run tests, you type python3 -m pytest tests/ --verbose --cov=src. When you want to format your code, it's black . && isort .. For linting, you run flake8 src tests. Before you…
Introduction
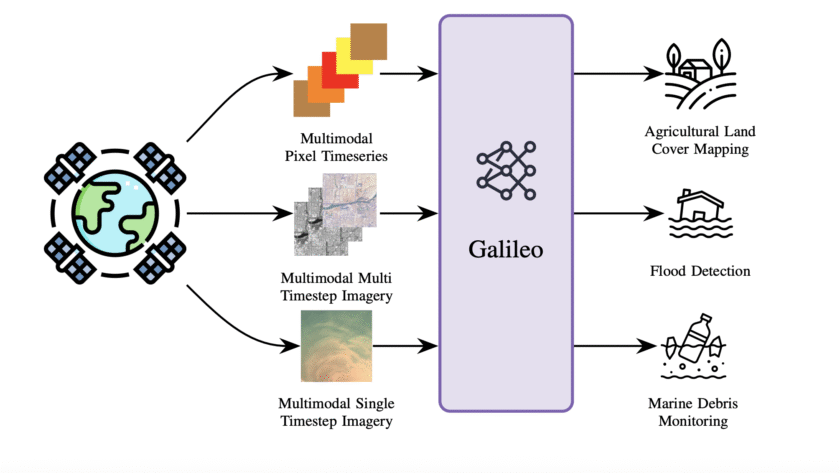
Galileo is an open-source, highly multimodal foundation model developed to process, analyze, and understand diverse Earth observation (EO) data streams—including optical, radar, elevation, climate, and auxiliary maps—at scale. Galileo is developed with the support from researchers from McGill University, NASA Harvest Ai2, Carleton University, University of British Columbia, Vector Institute, and Arizona State University.…

Acknowledgments Genie 3 was made possible due to key research and engineering contributions from Phil Ball, Jakob Bauer, Frank Belletti, Bethanie Brownfield, Ariel Ephrat, Shlomi Fruchter, Agrim Gupta, Kristian Holsheimer, Aleks Holynski, Jiri Hron, Christos Kaplanis, Marjorie Limont, Matt McGill, Yanko Oliveira, Jack Parker-Holder, Frank Perbet, Guy Scully, Jeremy Shar, Stephen Spencer, Omer Tov, Ruben…
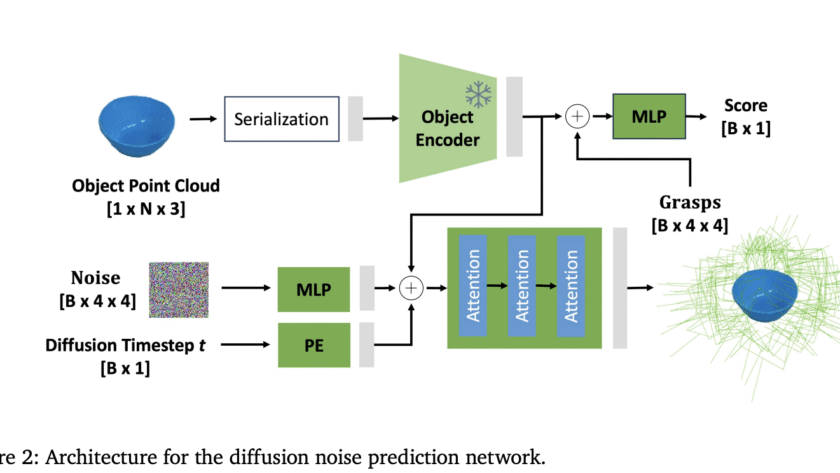
Robotic grasping is a cornerstone task for automation and manipulation, critical in domains spanning from industrial picking to service and humanoid robotics. Despite decades of research, achieving robust, general-purpose 6-degree-of-freedom (6-DOF) grasping remains a challenging open problem. Recently, NVIDIA unveiled GraspGen, a novel diffusion-based grasp generation framework that promises to bring state-of-the-art (SOTA) performance with unprecedented…
Testing... updates...updating now, making changes
Source link

Sponsored Content
Web data has become a key resource for businesses, whether you're running a startup or working at a Fortune 500 company. With the market projected to grow at a 13.2% CAGR through 2036, more companies are turning to web scraping solutions to collect and analyze data efficiently.
In this…
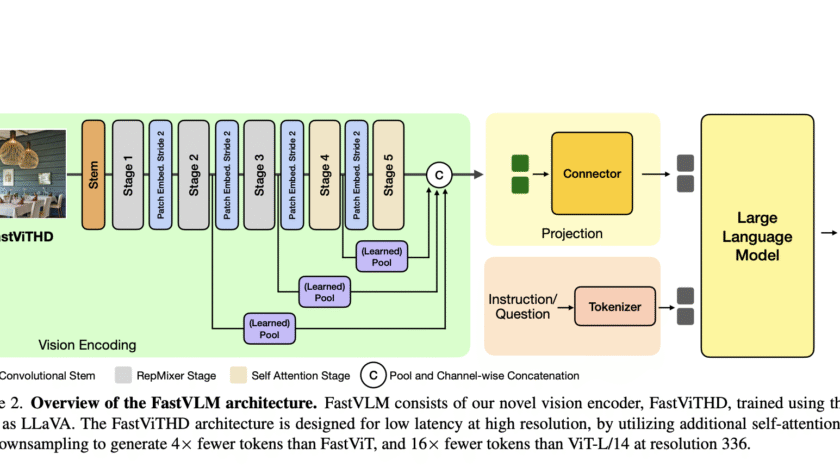
Vision Language Models (VLMs) allow both text inputs and visual understanding. However, image resolution is crucial for VLM performance for processing text and chart-rich data. Increasing image resolution creates significant challenges. First, pretrained vision encoders often struggle with high-resolution images due to inefficient pretraining requirements. Running inference on high-resolution images increases computational costs and latency…

Science
Published
30 July 2025
…
Estimated reading time: 5 minutes
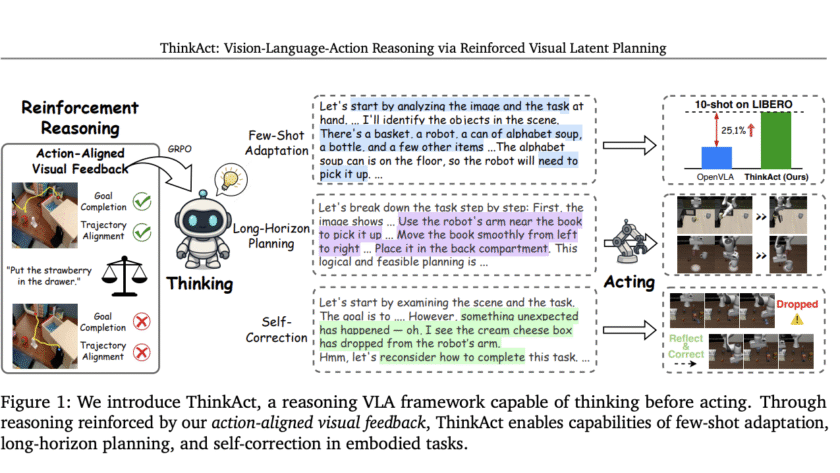
Introduction
Embodied AI agents are increasingly being called upon to interpret complex, multimodal instructions and act robustly in dynamic environments. ThinkAct, presented by researchers from Nvidia and National Taiwan University, offers a breakthrough for vision-language-action (VLA) reasoning, introducing reinforced visual latent planning to bridge high-level multimodal reasoning…