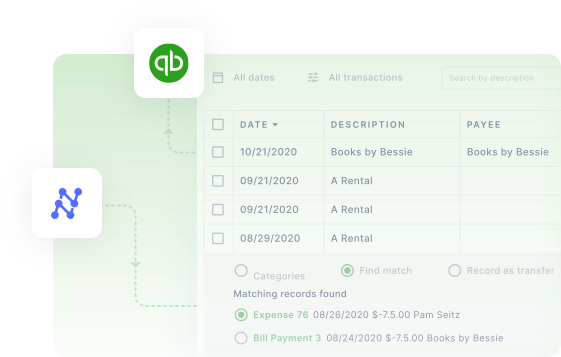
Marine robotic platforms support various applications, including marine exploration, underwater infrastructure inspection, and ocean environment monitoring. While reliable perception systems enable robots to sense their surroundings, detect objects, and navigate complex underwater terrains independently, developing these systems presents unique difficulties compared to their terrestrial counterparts. Collecting real-world underwater data requires complex hardware, controlled experimental setups,…