
testing webhooks
Source link
admin

Image by Author
Data science projects are notorious for their complex dependencies, version conflicts, and "it works on my machine" problems. One day your model runs perfectly on your local setup, and the next day a colleague can't reproduce your results because they have different Python versions, missing libraries, or incompatible system configurations.
This…
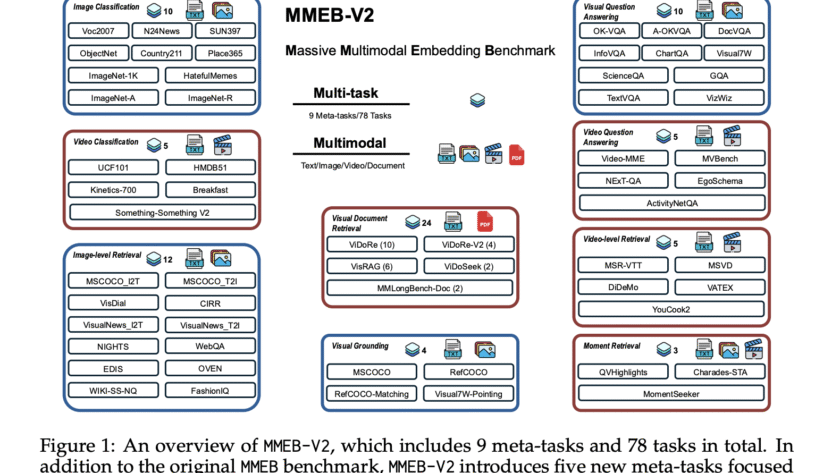
Embedding models act as bridges between different data modalities by encoding diverse multimodal information into a shared dense representation space. There have been advancements in embedding models in recent years, driven by progress in large foundation models. However, existing multimodal embedding models are trained on datasets such as MMEB and M-BEIR, with most focus only…
Today in the Gemini app, we're unveiling a new image editing model from Google DeepMind. People have been going bananas over it already in early previews — it's the top-rated image editing model in the world. Now, we're excited to share that it's integrated into the Gemini app so you have more control than ever…

Sponsored Content
DataCamp Free Access Week: Python + AI
Stop what you’re doing. DataCamp just unlocked an entire week of Python and AI learning—completely free. There’s no catch. No payment, no trial period, no commitment, no experience needed.
Whether you're starting from scratch or looking to build on technical…
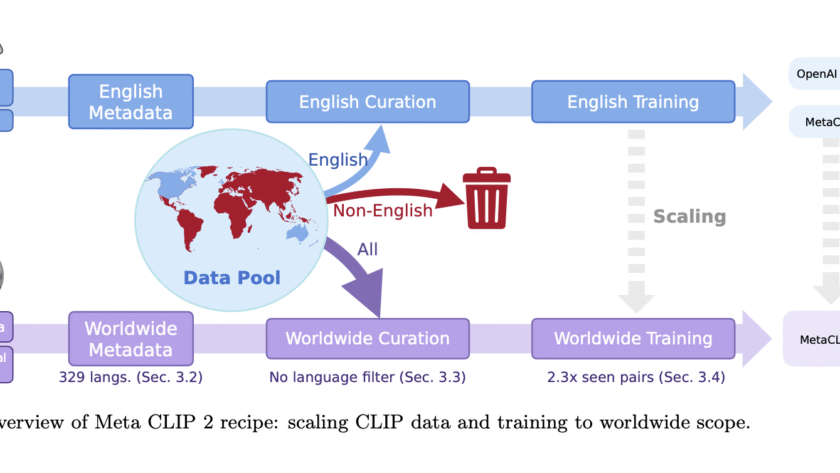
Contrastive Language-Image Pre-training (CLIP) has become important for modern vision and multimodal models, enabling applications such as zero-shot image classification and serving as vision encoders in MLLMs. However, most CLIP variants, including Meta CLIP, are limited to English-only data curation, ignoring a significant amount of non-English content from the worldwide web. Scaling CLIP to include…

Current AI benchmarks are struggling to keep pace with modern models. As helpful as they are to measure model performance on specific tasks, it can be hard to know if models trained on internet data are actually solving problems or just remembering answers they've already seen. As models reach closer to 100% on certain benchmarks,…
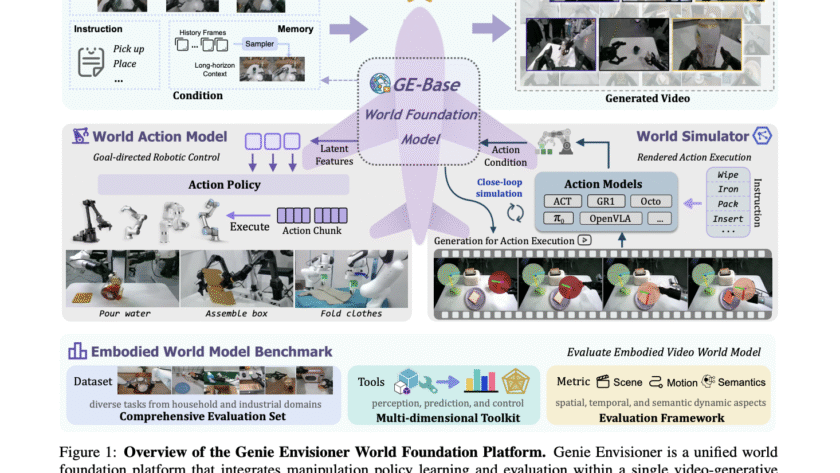
Embodied AI agents that can perceive, think, and act in the real world mark a key step toward the future of robotics. A central challenge is building scalable, reliable robotic manipulation, the skill of deliberately interacting with and controlling objects through selective contact. While progress spans analytic methods, model-based approaches, and large-scale data-driven learning, most…
For seven years, Wells Fargo lived with handcuffs. The 2018 Federal Reserve imposed asset cap froze the bank’s assets at ~$1.95 trillion, punishing it for governance and risk failures. While peers like Bank of America and PNC expanded balance sheets by 40%, Wells was flatlining. The cap slowed hiring, clouded strategy, and forced Wells to…
Beyond KYC: The New Battleground for Revenue Acceleration Studies show that when onboarding lag stretches into days, insurers lose up to 25% of prospective group business, as brokers and buyers drop off in frustration. And while sector-wide data specific to group onboarding drop-off is limited, insurance backlogs are well-documented to hamper growth and damage retention.…