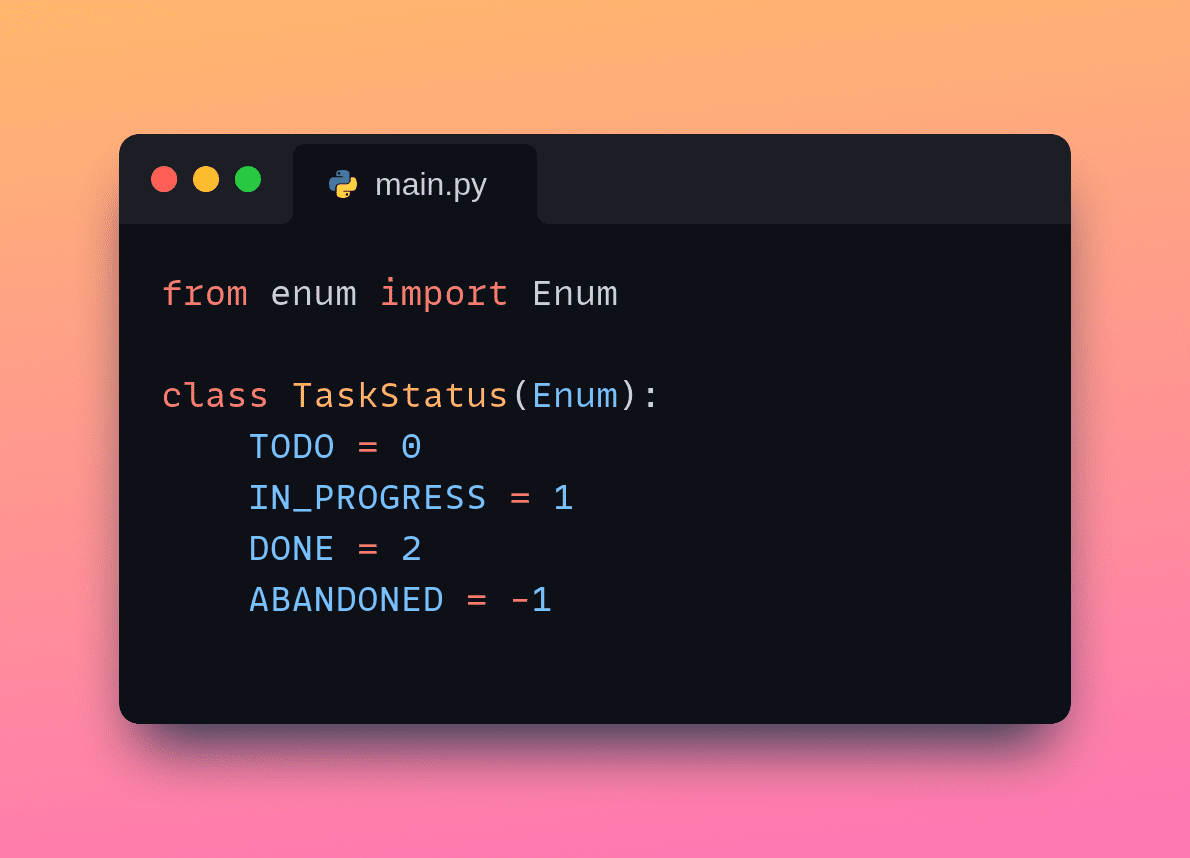
tl;dr version: A team of students helped design and carry out an experiment to determine whether bowls of Lucky Charms are equally “lucky” over the course of a box of cereal. Turns out, not so much. We estimate a decrease of approximately 2.7 total charms per additional bowl on average. This corresponds to more than…