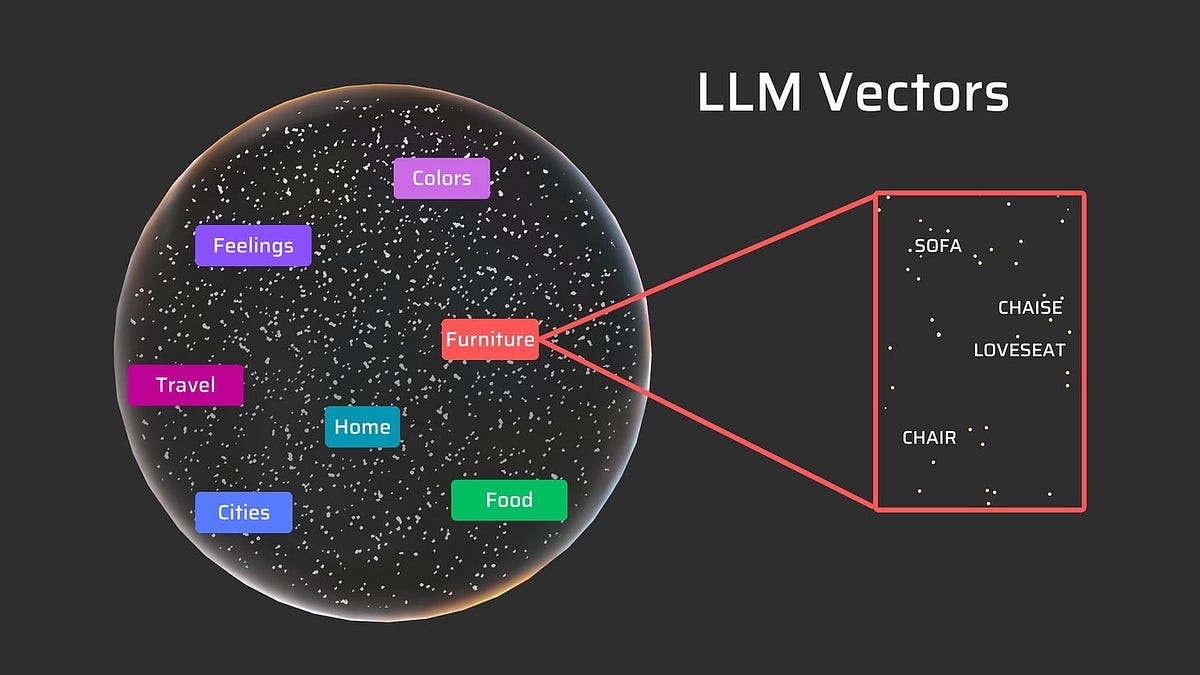
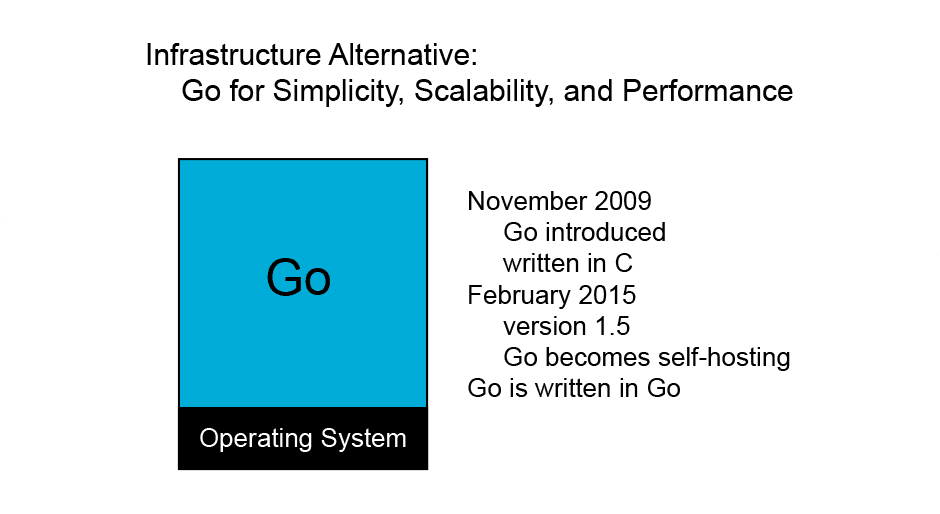
The Complete Guide to Understanding Large-Language Models and How to Work with Them. Originally Published on my Substack Have you ever wondered how a chatbot like ChatGPT or any other Large Language Model (LLM) works? When a new technology really wows and gets us excited, it becomes a part of us. We make it ours,…