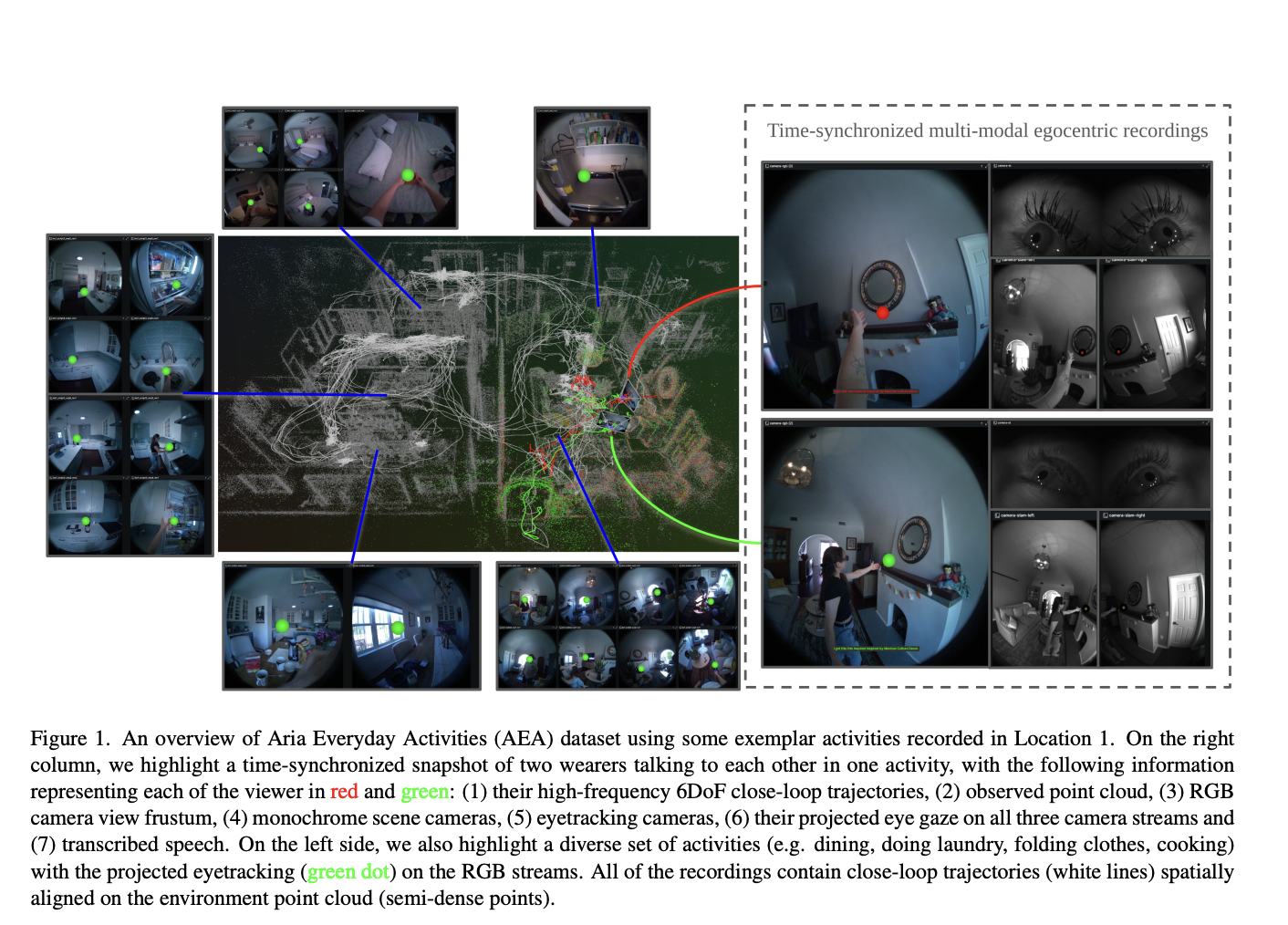
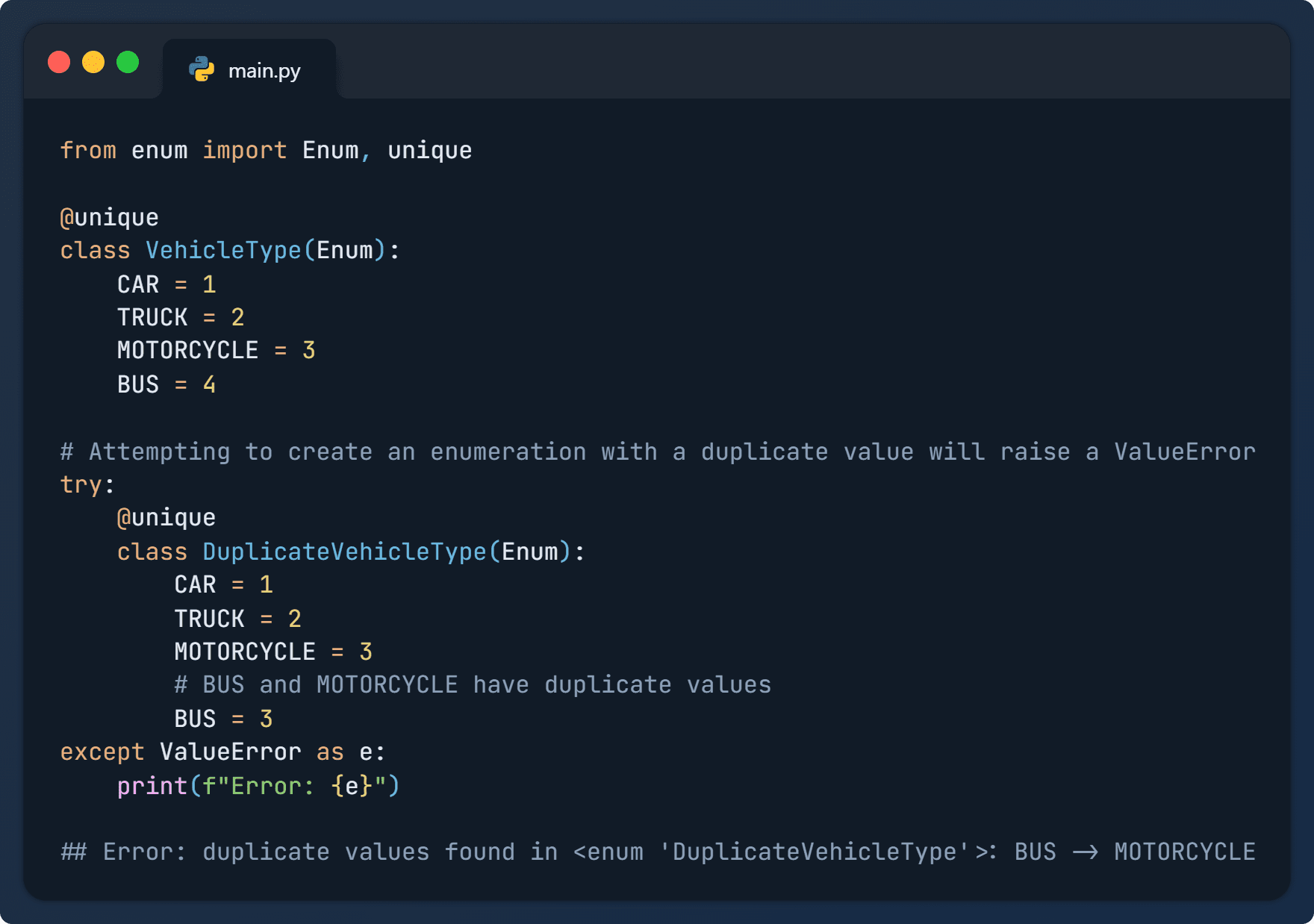
It’s 2024, so I shouldn’t need to tell you why you ought to learn Python if you’re thinking about doing any kind of coding job. It’s one of the most popular programming languages, almost every data science job loves to see it on your resume, and it’s one of the easiest languages to learn.…