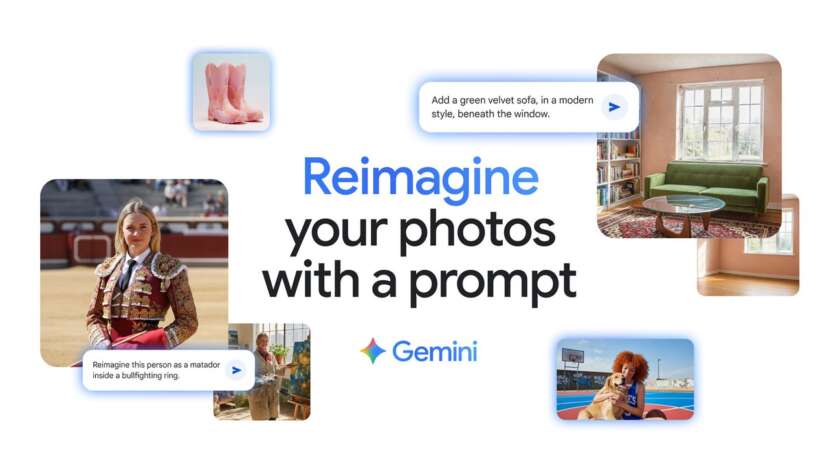
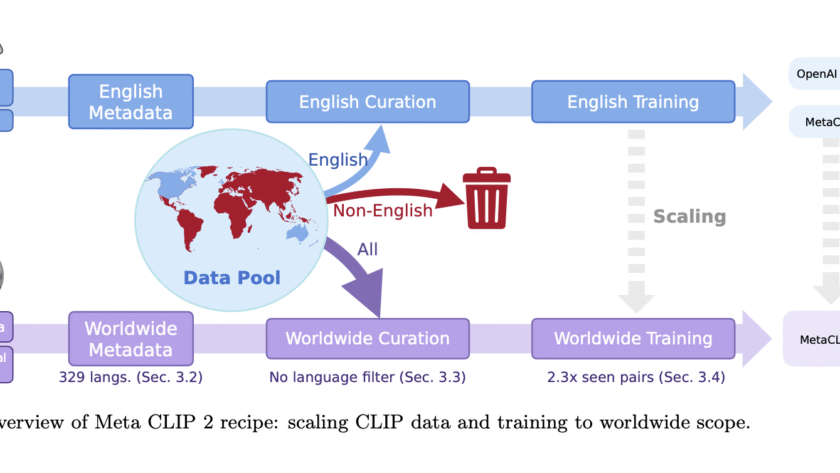
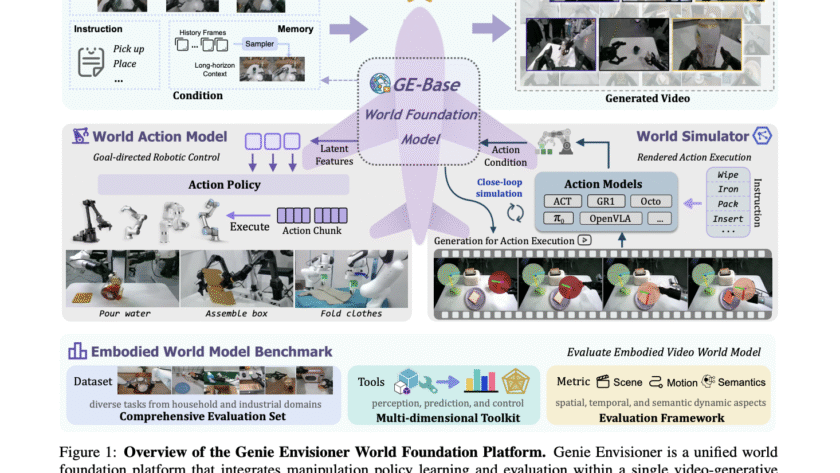
Today in the Gemini app, we're unveiling a new image editing model from Google DeepMind. People have been going bananas over it already in early previews — it's the top-rated image editing model in the world. Now, we're excited to share that it's integrated into the Gemini app so you have more control than ever…