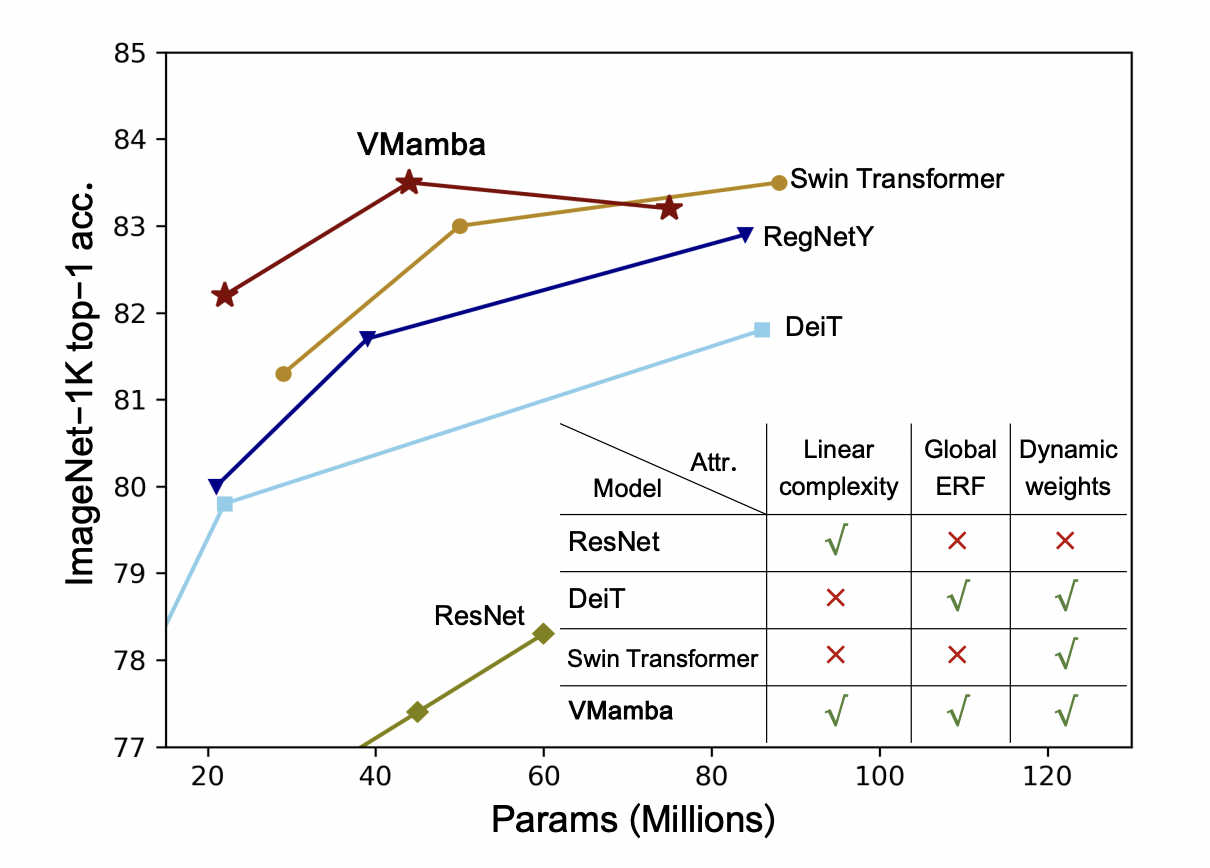
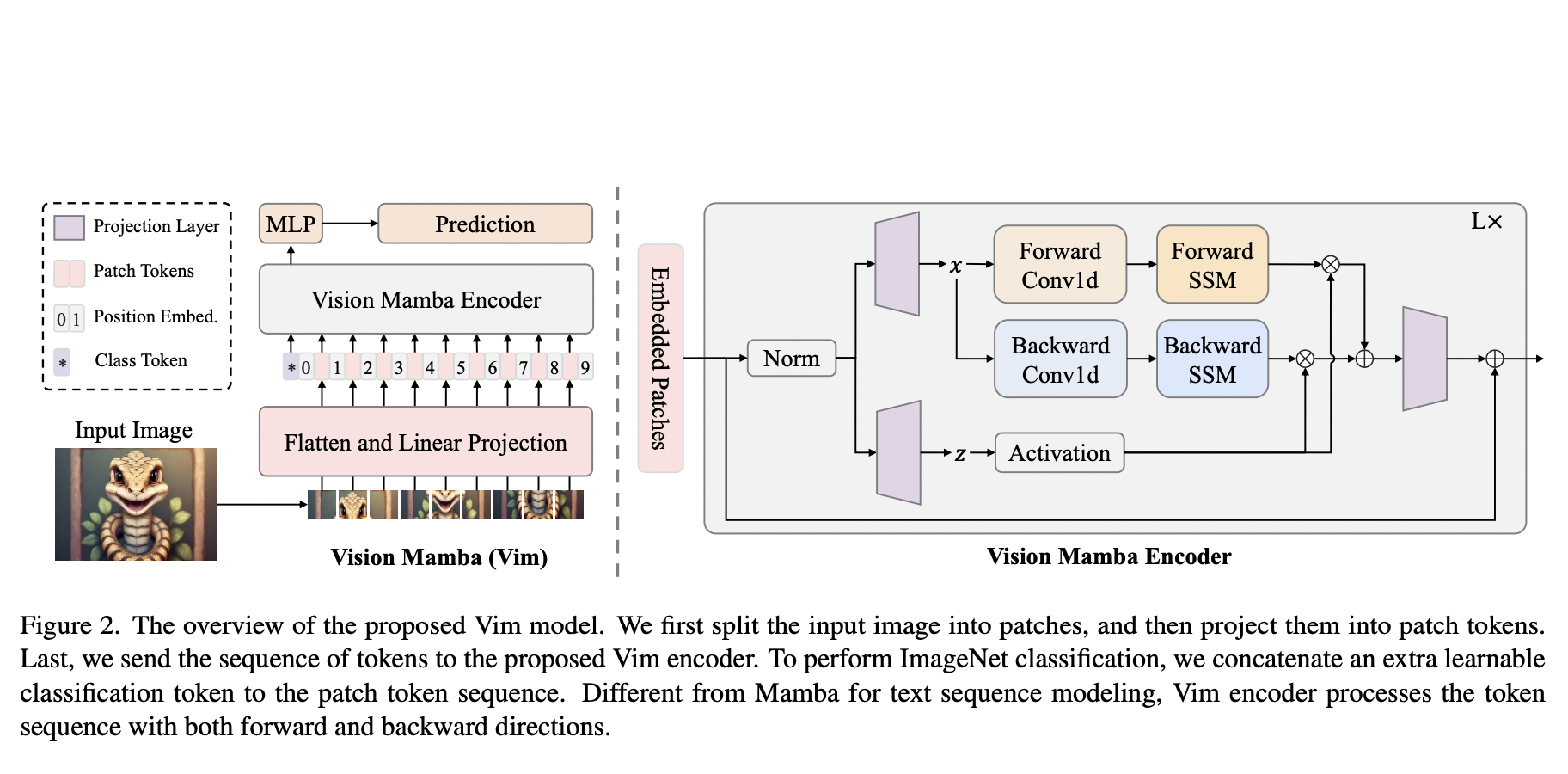
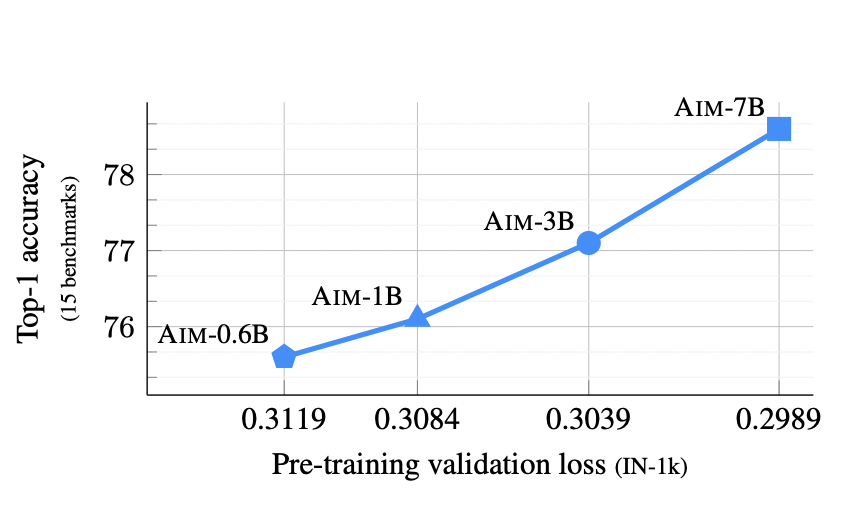
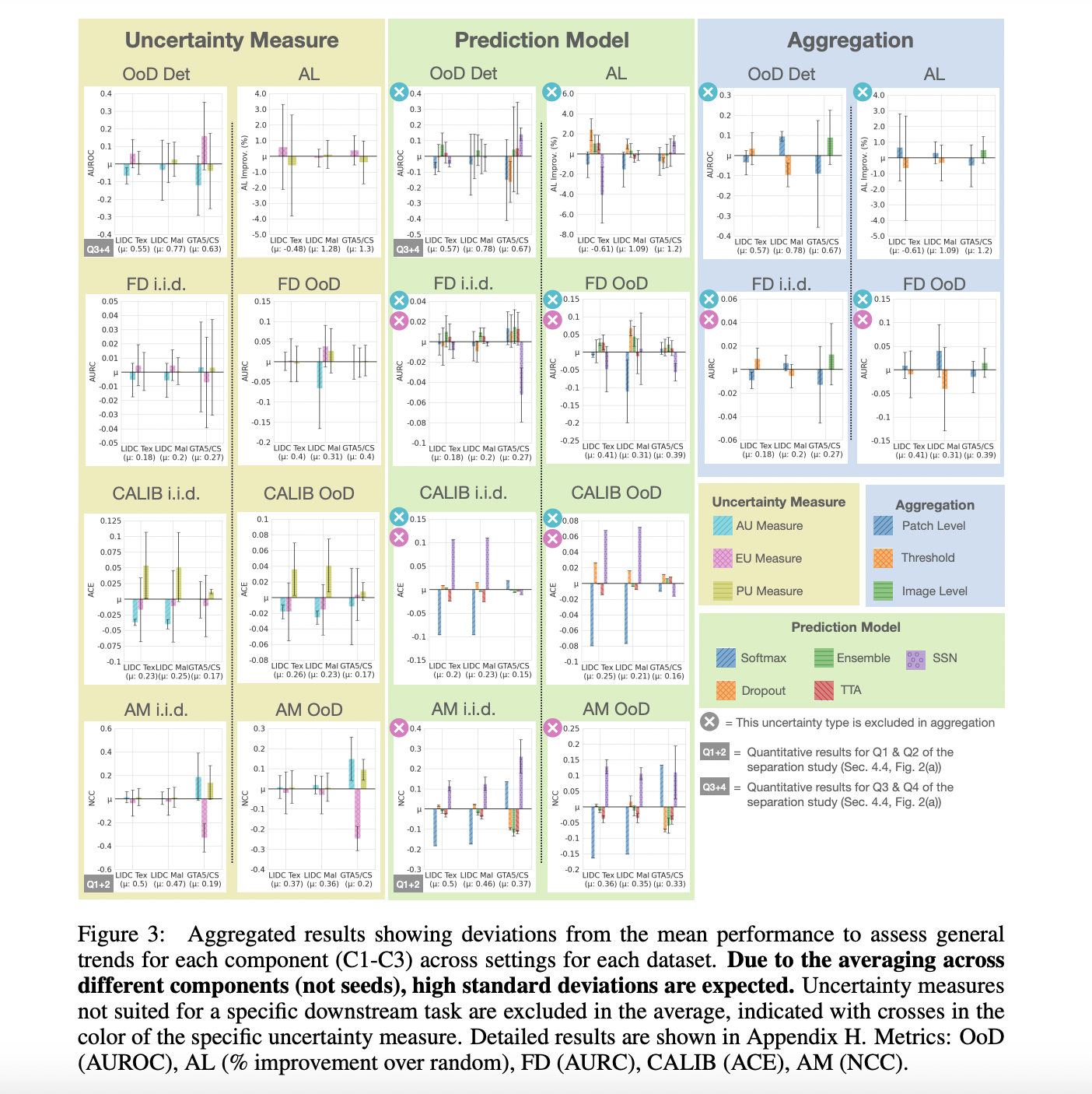
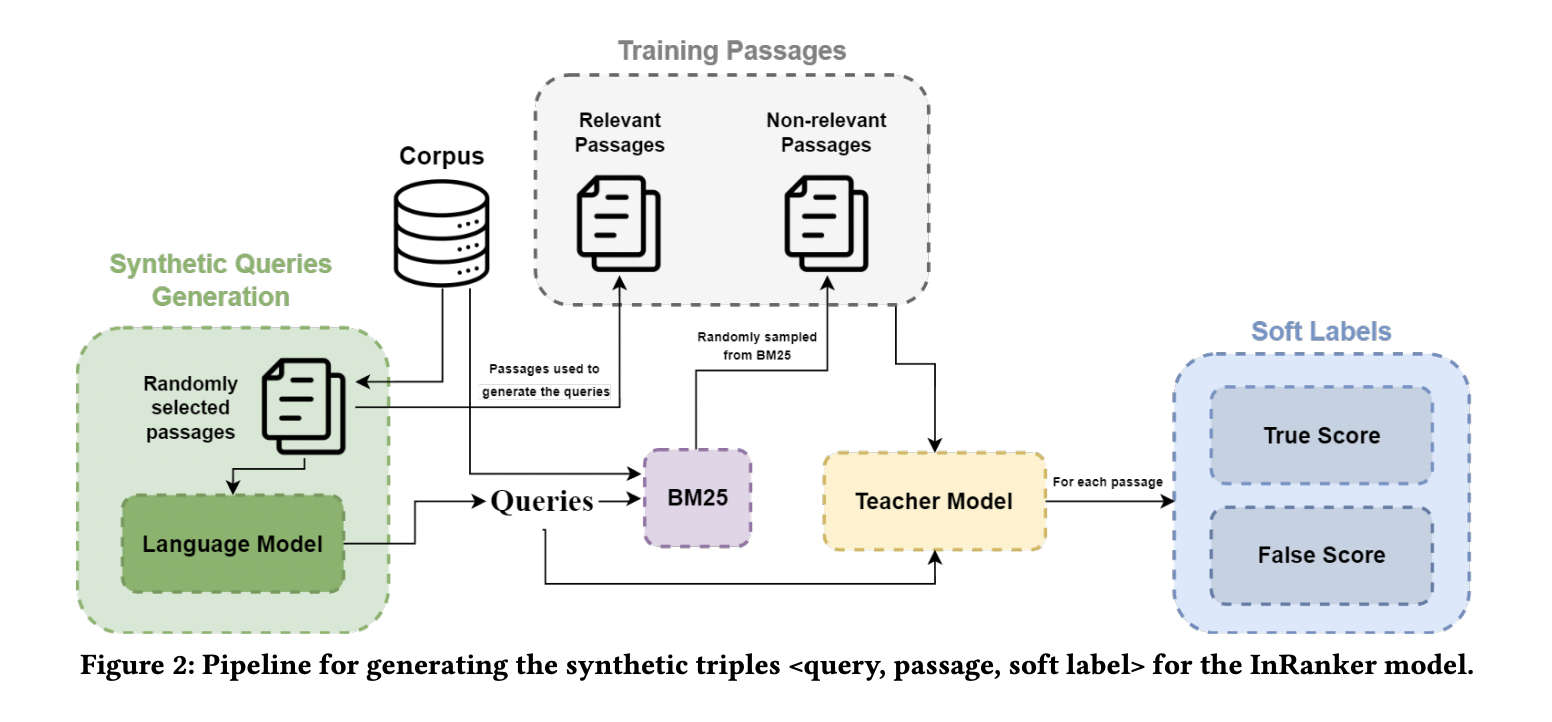
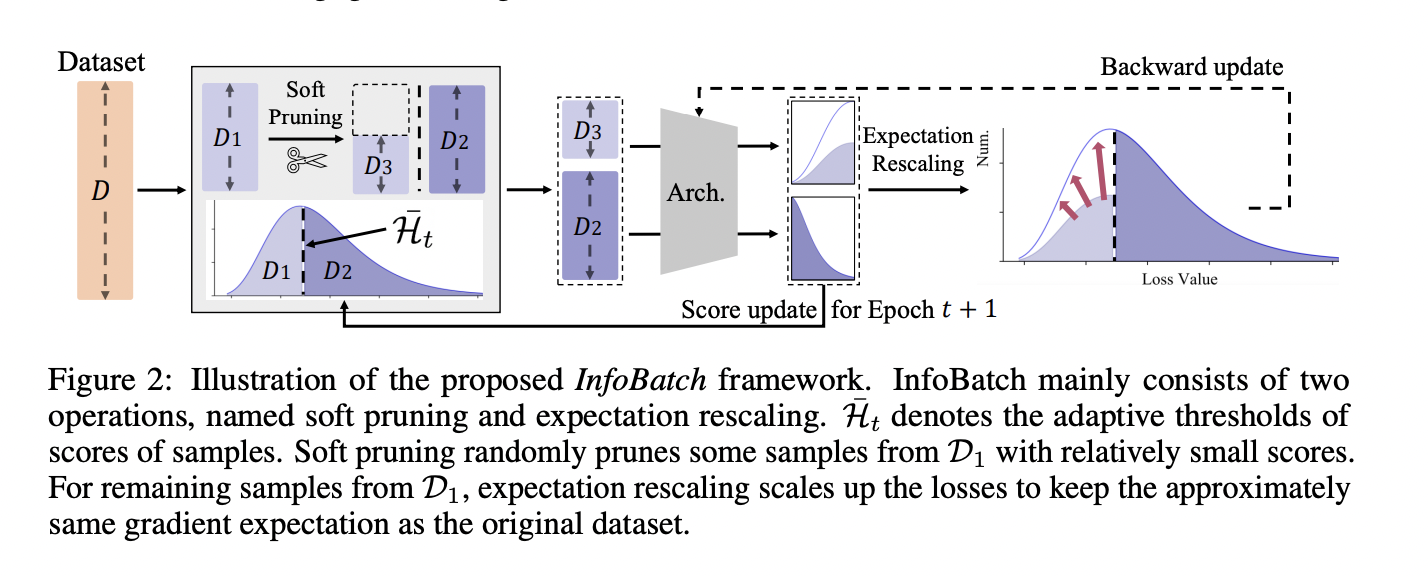
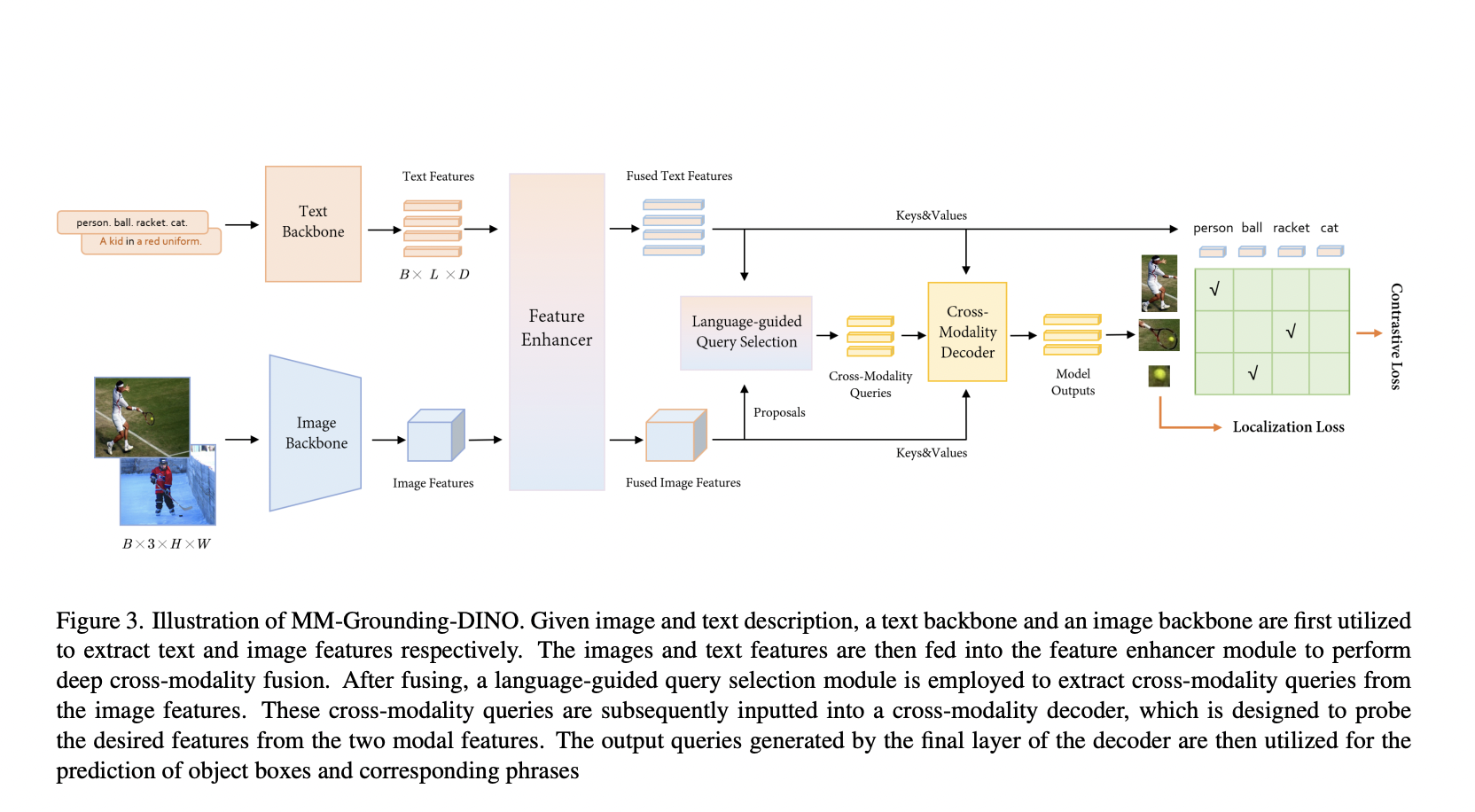
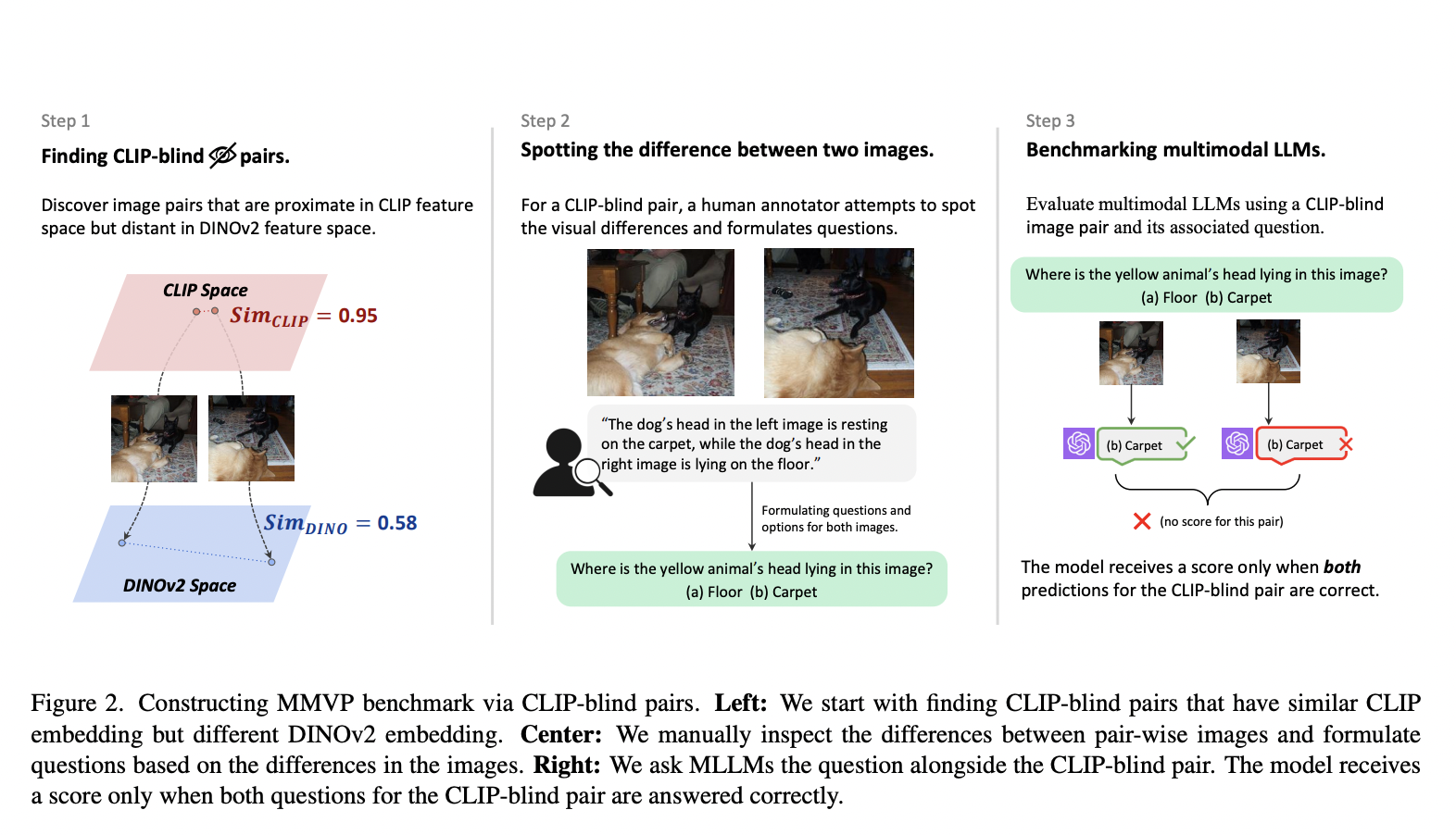
There are two major challenges in visual representation learning: the computational inefficiency of Vision Transformers (ViTs) and the limited capacity of Convolutional Neural Networks (CNNs) to capture global contextual information. ViTs suffer from quadratic computational complexity while excelling in fitting capabilities and international receptive field. On the other hand, CNNs offer scalability and linear complexity…