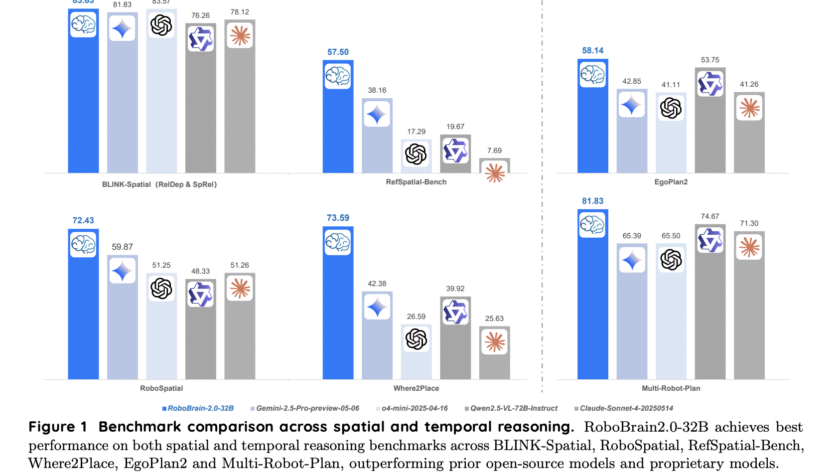
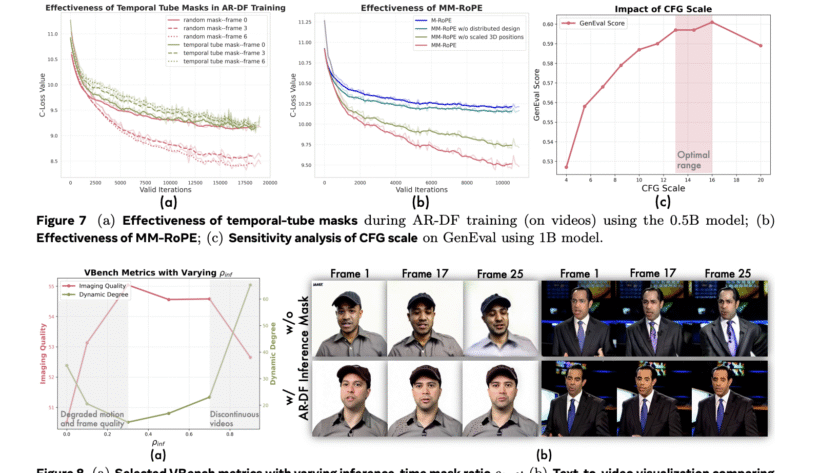
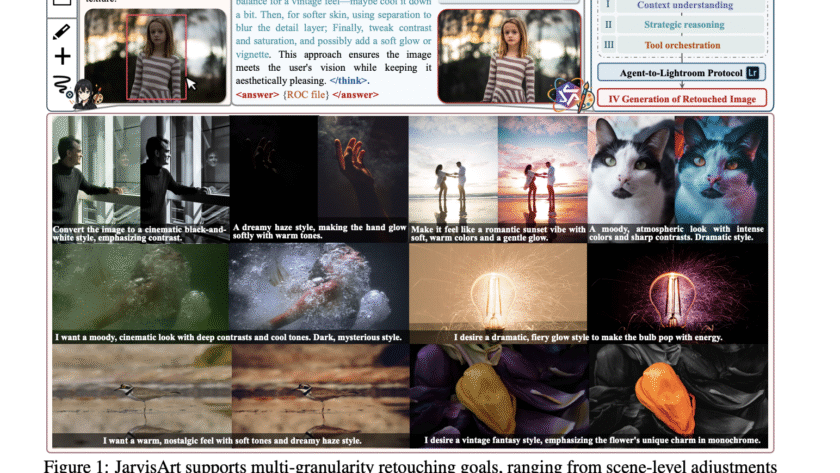
In the domain of multimodal AI, instruction-based image editing models are transforming how users interact with visual content. Just released in August 2025 by Alibaba’s Qwen Team, Qwen-Image-Edit builds on the 20B-parameter Qwen-Image foundation to deliver advanced editing capabilities. This model excels in semantic editing (e.g., style transfer and novel view synthesis) and appearance editing…