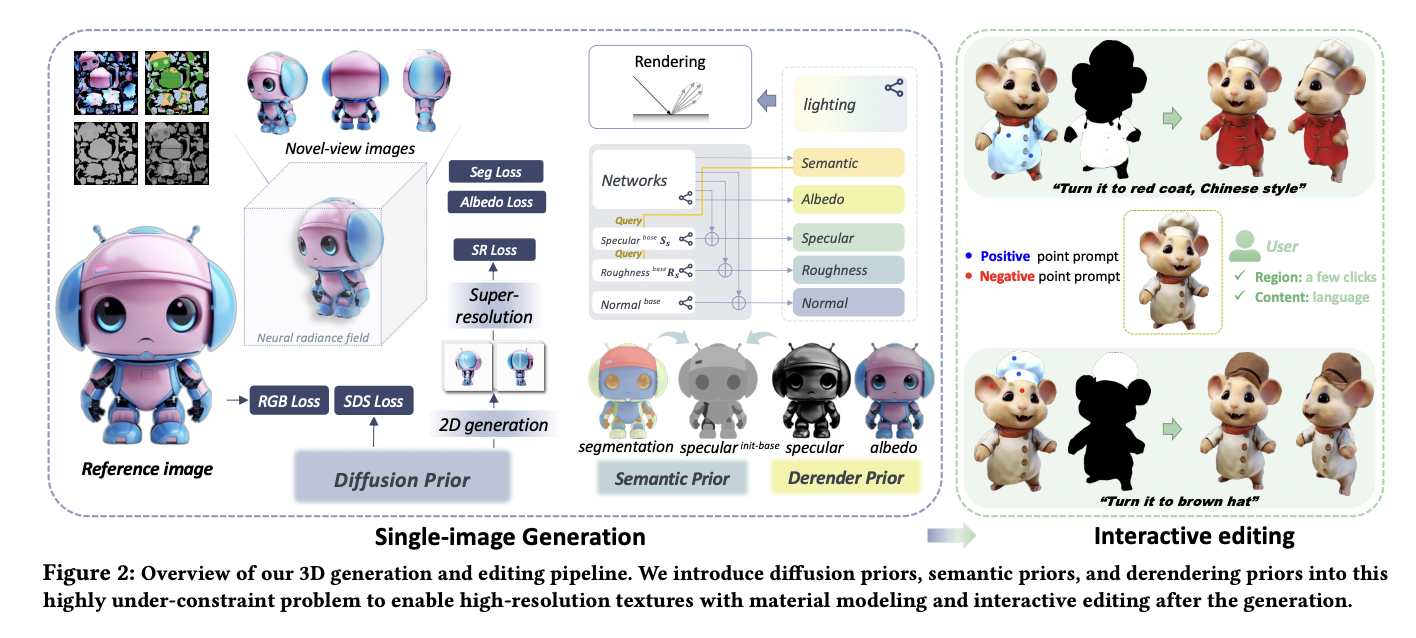
It isn’t easy to generate detailed and realistic 3D models from a single RGB image. Researchers from Shanghai AI Laboratory, The Chinese University of Hong Kong, Shanghai Jiao Tong University, and S-Lab NTU have presented HyperDreamer to address this issue. This framework solves this problem by enabling the creation of 3D content that is viewable,…